Gastbeitrag BuDe:
Data Science bei der Bayerischen
In der heutigen, schnelllebigen digitalen Ära spielen Daten eine entscheidende Rolle in der Unternehmensführung und -entwicklung. Data Science hat sich als ein Schlüsselelement für den Fortschritt in verschiedenen Branchen etabliert. Im folgenden Artikel wollen wir euch einen detaillierten Einblick in die Welt der Data Science geben, wobei speziell die Anwendungen und Herausforderungen dieser Disziplin in der Praxis beleuchtet werden.
Was versteht man unter Data Science?
Data Science ist eine angewandte, fachübergreifende Wissenschaft, die Methoden und Wissen aus den Bereichen der Mathematik und Informatik nutzt. Data Science verfolgt das Ziel, Wissen aus Daten zu generieren. Dies umfasst unter anderem die Ableitung von Handlungsempfehlungen aus Daten, Unterstützung der Entscheidungsfindung und Unternehmenssteuerung, Optimierung und Automatisierung von Unternehmensabläufen und das Prognostizieren zukünftiger Ereignisse. Im Versicherungswesen kann Data Science vor allem dazu beitragen, sich kundenzentrierter auszurichten und dadurch einen Wettbewerbsvorteil zu generieren.
Bedeutung von Daten
Die unabdingbare Ressource für KI und Data Science Projekte sind Daten. Die Schwierigkeit hierbei ist es, die richtigen Daten zu finden, zu kombinieren und so aufzubereiten, dass sie sich zur Analyse und für komplexere Modelle nutzen lassen. Liegen die nötigen Daten in der passenden Form vor, so geht es an die Auswahl des Modells. Das Modell muss sowohl mit den Daten umgehen können als auch für den gegebenen Use-Case Sinn ergeben. Im Anschluss kann dann das Machine-Learning-Modell trainiert, getestet und schließlich produktiv genutzt werden. Die Vorgehensweise ist ein iterativer Prozess, bei dem die einzelnen Schritte zunehmend besser ineinander übergreifen, sodass optimale Ergebnisse erzielt werden können.
Data Science in der BIT
Seit Kurzem haben wir im Data & Analytics Team begonnen, uns vertieft mit Data Science Methoden und dazugehörigen Use-Cases zu beschäftigen. Zunächst haben wir uns mit einer eher allgemeinen Aufbereitung und Analyse der bereits vorhandenen Daten aus dem Datalake beschäftigt und im Anschluss einige Verfahren und Use-Cases getestet und bewertet.
Zuerst wurde ein dichtebasiertes Clustering-Verfahren zur Customer-Segmentation getestet, das einige technische Schwierigkeiten mitbrachte und ein Schlaglicht auf die Problematik der allgemeinen Datenverfügbarkeit warf. Die Ergebnisse des Clusterings waren eher unbrauchbar, aber dennoch sind wir sicher, dass das Verfahren in anderen Kontexten sicher bessere Ergebnisse erzielen kann.
Abbildung 1: Beispiel Clustering
Danach wurde ein logistisches Regressionsmodell trainiert, um Kundenreaktionen im Kontext von Marketing-Kampagnen vorherzusagen. Hierfür mussten ebenfalls einige technische Hürden wie etwa unbalancierte Daten überwunden werden. Das Modell half schließlich dabei, die Reaktionen auf die analysierte Kampagne besser zu verstehen. Bei der Verwendung weiterer Datenquellen und weiterer Kampagnendaten erhoffen wir uns noch deutlich belastbarere Ergebnisse, mit denen das Budget einer Kampagne noch zielgerichteter verwendet werden kann.
Am erfolgreichsten war jedoch ein Ansatz, mit dem Kunden klassifiziert wurden. Dabei ließen sich nur mittels allgemeiner Daten und einem einfachen logistischen Regressionsmodell Scooter-Kunden von anderen mit über 97% Genauigkeit (Precision 78.4%, Recall 93.7%, Specificity 97.4%) unterscheiden. Auch weitere Qualitätskriterien für das Modell waren hervorragend (AUC=0.989, McFadden Pseudo-R²=0.732) und deuten an welches Potential in einem solchen Ansatz steckt. Die aus dem Modell resultierenden Erkenntnisse könnten dabei weitere Verwendung in Cross-Selling-Aktionen für Scooter-Kunden finden.
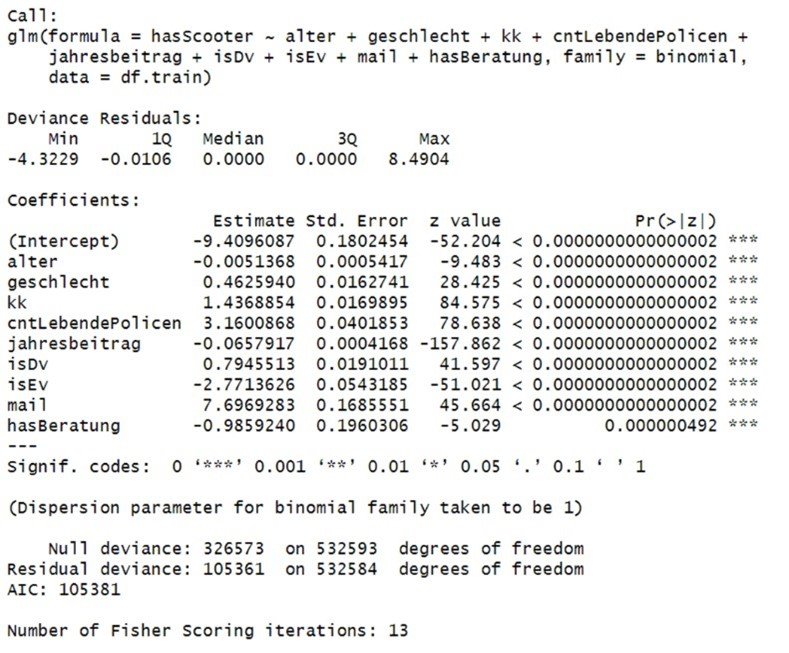
Abbildung 3: Logistisches Regressionsmodell zur Klassifikation von Scooter-Kunden
Ziele und Ausblick
Unser Ziel im Data & Analytics Team ist allgemein der Einsatz von Data-Science Verfahren, um zielgruppenspezifische, tiefergehende Datenanalyse und Predictive Analytics zu ermöglichen. Dabei möchten wir in Zusammenarbeit mit Stakeholdern Zusammenhänge von Daten, Personen und Reaktionen erkennen und daraus Rückschlüsse ziehen. Mit diesen Rückschlüssen wollen wir mithelfen, das Verhalten unserer Kundinnen und Kunden noch besser zu verstehen und gegebenenfalls sogar vorhersagen zu können.
Bei den nächsten Schritten liegt der Fokus auf der Zusammenführung weiterer Datenquellen und der Optimierung der Datenqualität. Auch allgemeines Verständnis für die Daten und darin enthaltene Zusammenhänge sind immer noch von großer Bedeutung. Dies geht dabei Hand in Hand mit dem Erarbeiten von weiteren Use-Cases und dem Testen verschiedener Ansätze und Modelle. Denkbar sind weitere Use-Cases wie beispielsweise Stornoprävention oder das Erstellen individualisierter Angebote über Next-Best-Offer-Verfahren.
Wir gehen davon aus, dass sich diese Data Science Methoden und Verfahren in weiteren Tests bewähren werden, sodass wir sie mittelfristig auch produktiv verwenden können. Denn durch die Verwendung und Analyse von Daten lassen sich nachvollziehbare Handlungsempfehlungen ermitteln, die die Bayerische weiter voranbringen werden.
Sophie Rutka, Erik Dahm, Johannes Müller
Data science